Youtube Scraper API
Extract comprehensive YouTube comment data—from IDs and content to engagement metrics—with full-process control, seamless scaling, and reliable, high-efficiency performance.
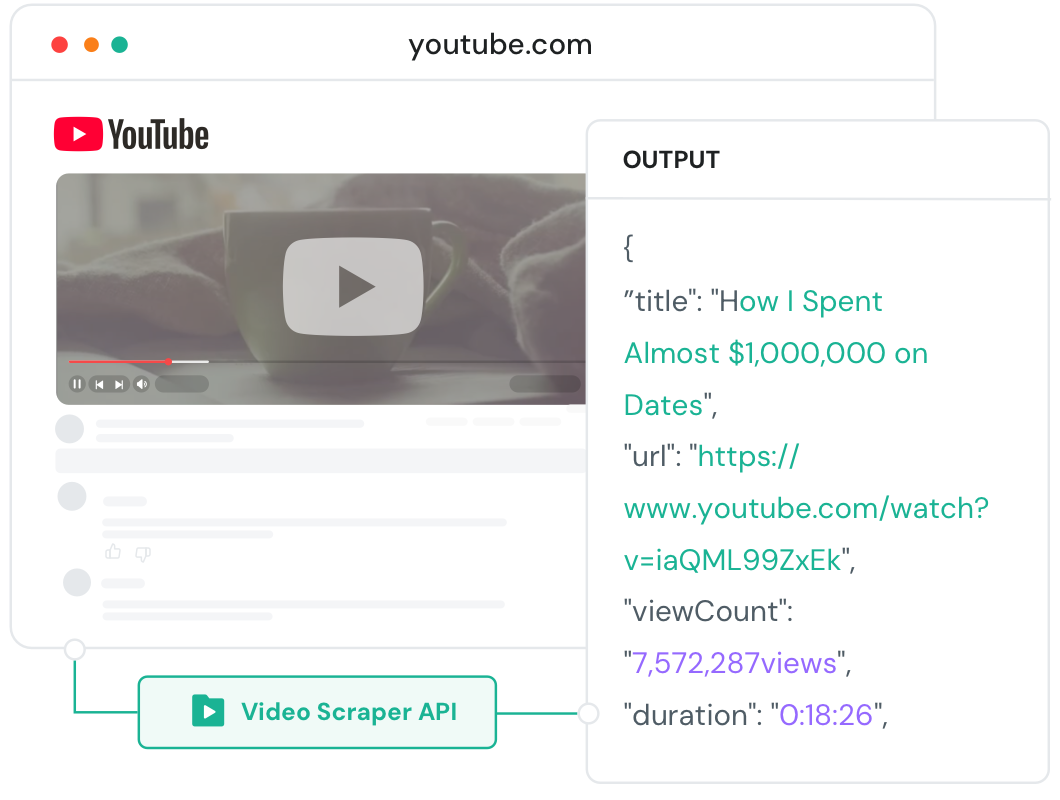
Extract comprehensive YouTube comment data—from IDs and content to engagement metrics—with full-process control, seamless scaling, and reliable, high-efficiency performance.
No more rate limits, blocks or yt- dlp failures. Just stable, petabyte-scale video data extraction for AI training
Video & Audio Download | Text & Subtitles | Complete Video Comment | Video Metadata |
Video & Audio Download |
Text & Subtitles |
Complete Video Comment |
Video Metadata |
Just a few simple steps to get clear, structured YouTube data.
01Discover and evaluate videos STEP1.1 Parse and access video resources directly using a video ID or URL | 02Download videos and subtitles STEP2.1 Download video/audio contentSTEP2.2 Retrieve video transcripts | 03Cloud sync and export STEP3.1 Automatically uploads data to your specified cloud storageSTEP3.2 Generates shareable links and provides API access |
01Discover and evaluate videos STEP1.1 Parse and access video resources directly using a video ID or URL |
02Download videos and subtitles STEP2.1 Download video/audio contentSTEP2.2 Retrieve video transcripts |
03Cloud sync and export STEP3.1 Automatically uploads data to your specified cloud storageSTEP3.2 Generates shareable links and provides API access |
YouTube-Video Detail
import requests
params = {"locale":"en-US","context":{"url_list":[{"url":"https://www.youtube.com/watch?v=_KbiMHvpvSQ"}]}}
headers = {"Authorization": "YOU_TOKEN", "Content-Type": "application/json"}
response = requests.post("https://xcrawl.com", headers=headers, json=params)
print(response.json())Automate video data collection and preparation to fuel your AI model training with reliable, scalable datasets.
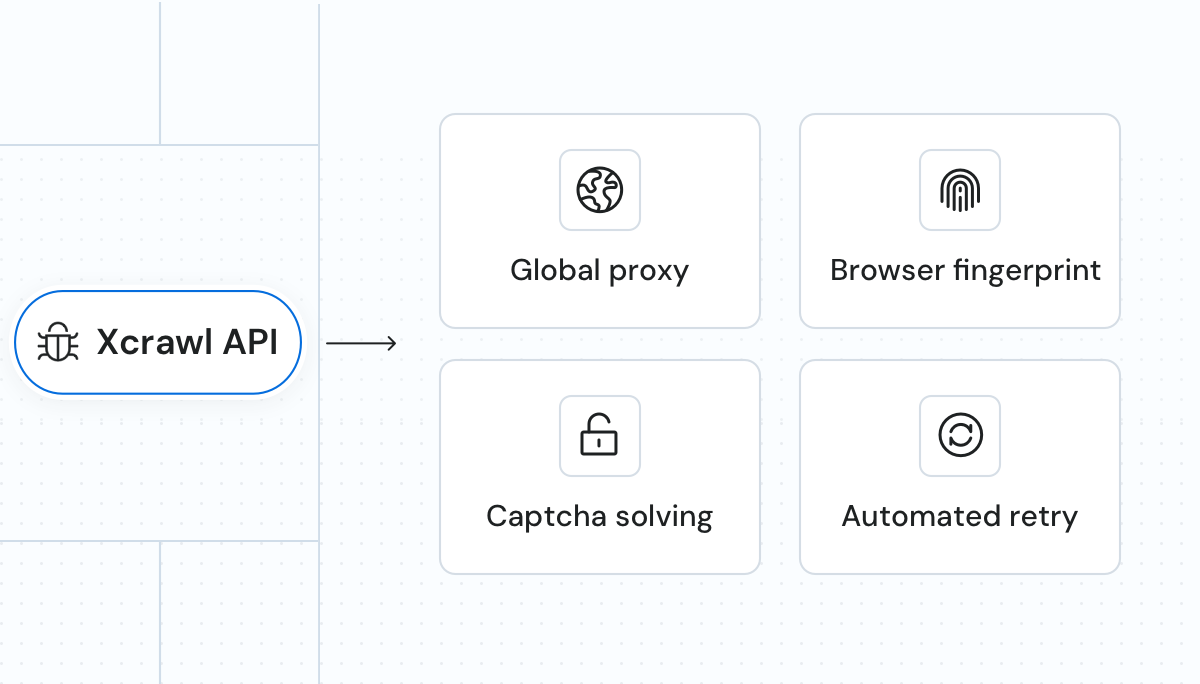
Proxy managementML-driven proxy selection and rotation using our premium proxy pool from 190 countries. | AI-driven fingerprintingUnique HTTP headers, JavaScript, and browser fingerprints ensure resilience to dynamic content. | CAPTCHA bypassAutomatic retries and CAPTCHA bypassing for uninterrupted data retrieval. |
Bulk data extractionExtract data from several pages at the same time with up to 10K URLs per batch. | Multiple delivery optionsReceive data via cloud storage such as SFTP or AWSS3, or retrieve results through APIs. | Scheduled scrapingSet your preferred frequency for automated, custom-timed data collection, with results delivered directly to your cloud storage. |
Maintenance-free infrastructureEliminate proxy maintenance and infrastructure hassle. No need to build crawler systems. | Highly scalableEasy to integrate with support for customization. | 24/7 supportReceive professional support in case of anyquestions or issues. |
Proxy managementML-driven proxy selection and rotation using our premium proxy pool from 190 countries. |
AI-driven fingerprintingUnique HTTP headers, JavaScript, and browser fingerprints ensure resilience to dynamic content. |
CAPTCHA bypassAutomatic retries and CAPTCHA bypassing for uninterrupted data retrieval. |
Get LLM-ready data
We deliver structured, AI-compatible data, making YouTube videos, transcripts, subtitles, metadata, and search results ready for seamless integration into LLMs, AI models, and analytics workflows.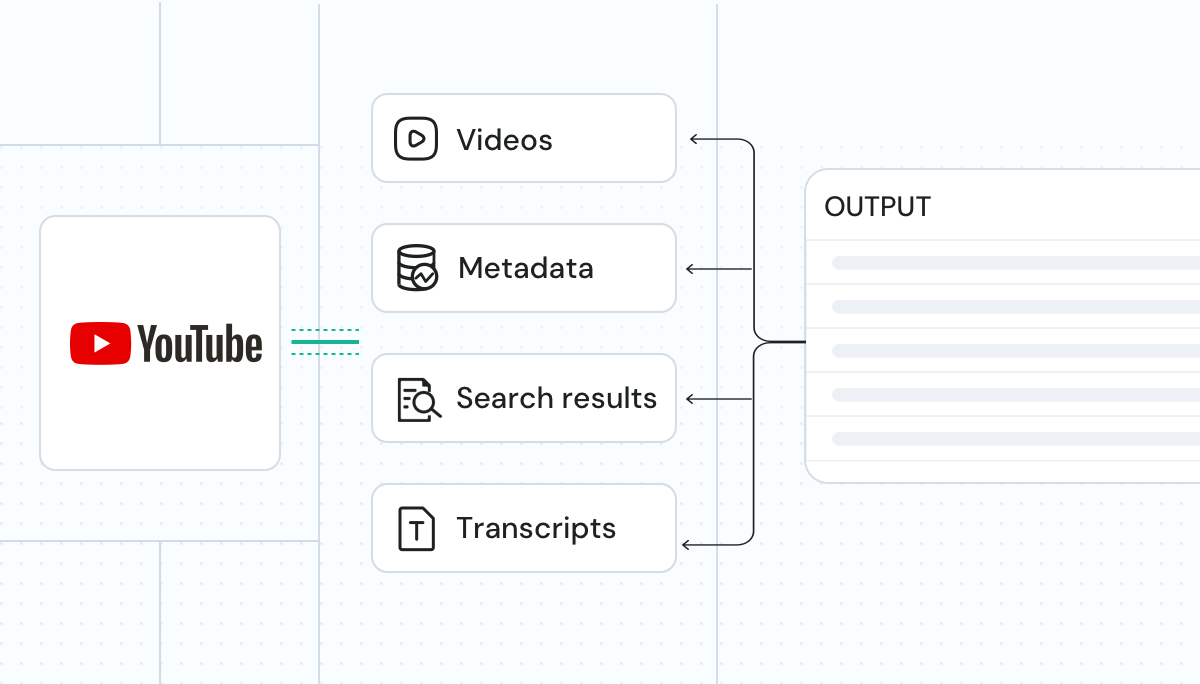
Data services. No maintenance.
Access high-quality video data from real web traffic worldwideEverything you need to know about Xcrawl.



