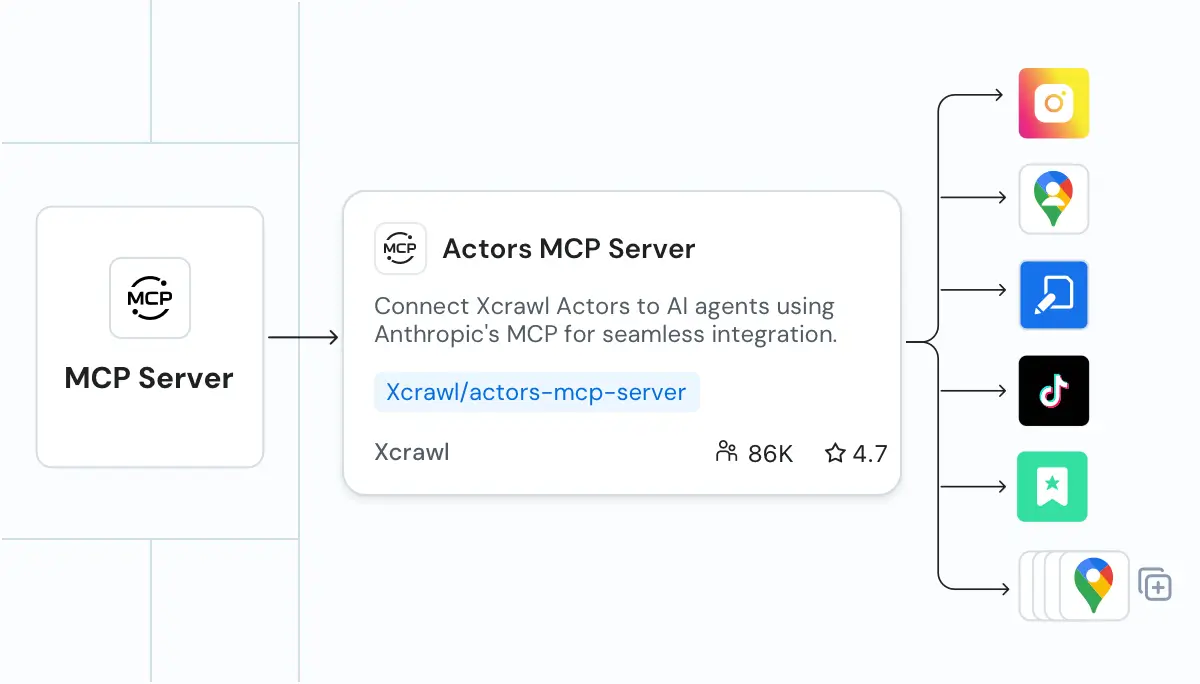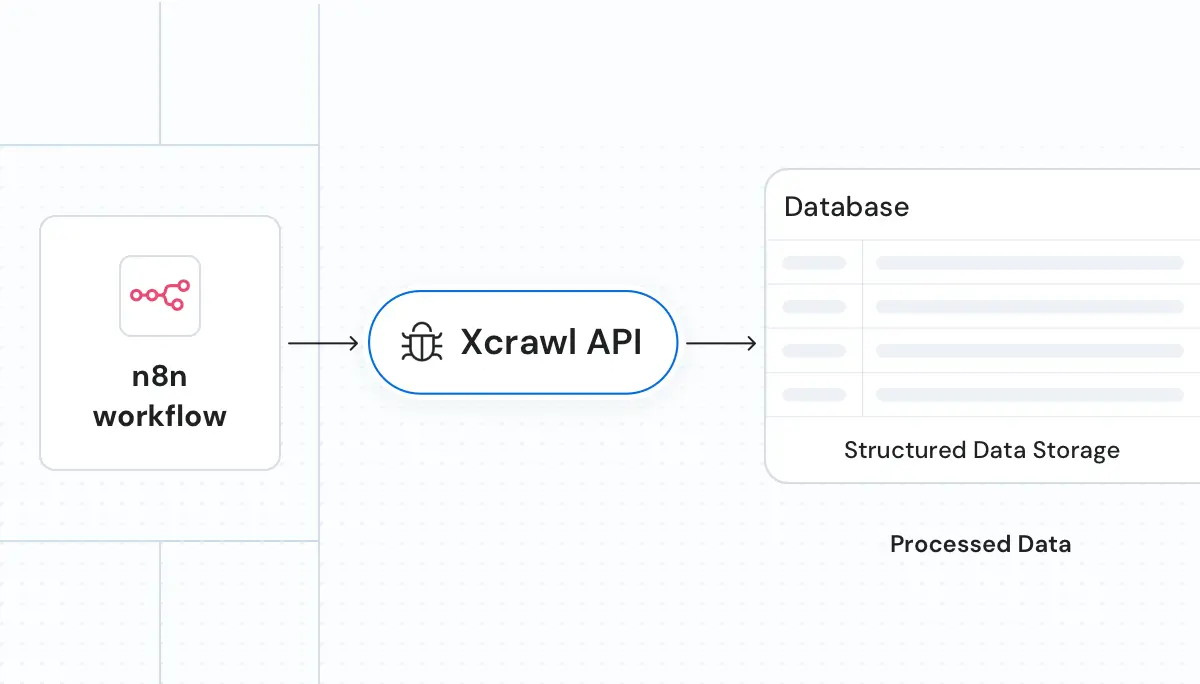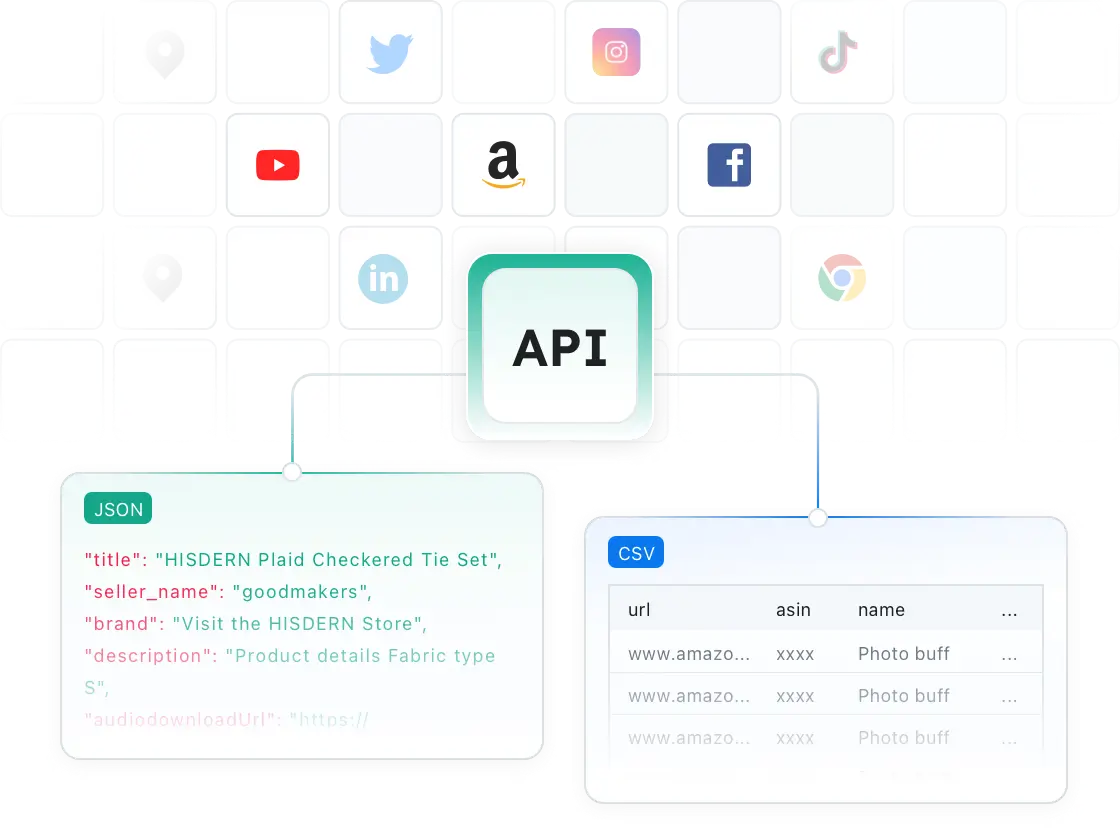
构建 AI 就绪的数据管道
为你的 LLM、Agent 以及分析管道提供实时结构化数据,无需复杂配置。
用真实、实时的数据驱动你的 AI 模型与自动化流程。
Xcrawl 能抓取任意网站——SERP、社交媒体、电商、视频、新闻等,并提供 JS 渲染、反爬绕过与结构化输出。
API for finding YouTube videos by searching with specific keywords or phrases.














为你的 LLM、Agent 以及分析管道提供实时结构化数据,无需复杂配置。
具备从数千到数百万次请求的全套数据采集功能。



从数千扩展到数百万请求都轻而易举,并有 99.9% 稳定性支持。
我们只采集公开数据Fully compliant with US and EU regulations — 100% legal and safe.
我们的 API 上手简单,几分钟即可开始采集数据。
无需手动轮换代理或管理 IP — 我们自动处理,并内置重试机制。
像真实浏览器一样抓取页面,无论是 React、Angular、Vue 或任何框架。
由负责维护采集器的核心团队直接提供技术支持,而非客服外包。
适用于任何规模的安全且可靠的网页数据提取服务。99.95% 在线率,符合 SOC2、GDPR 与 CCPA 要求。






关于 Xcrawl 的所有核心信息。