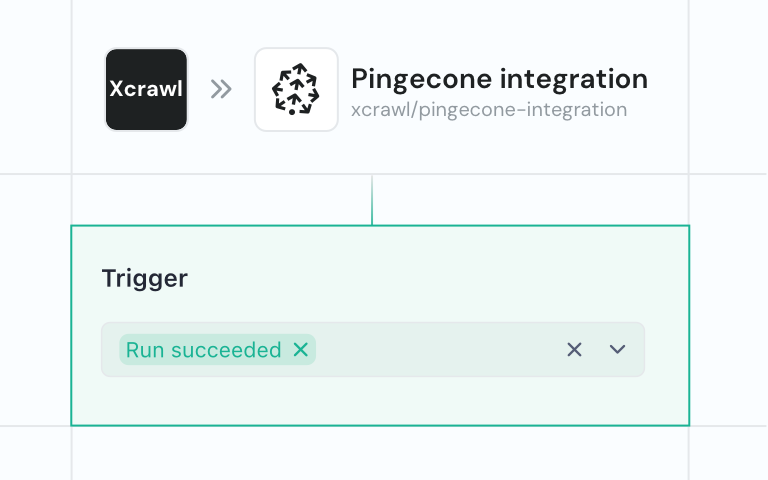
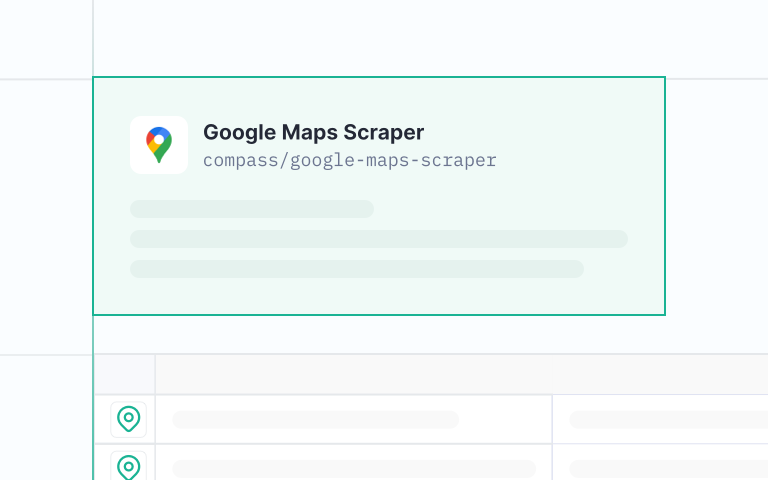
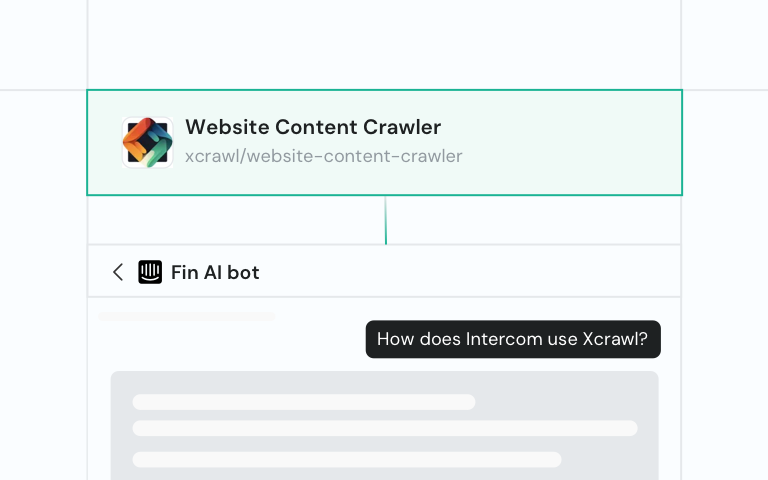
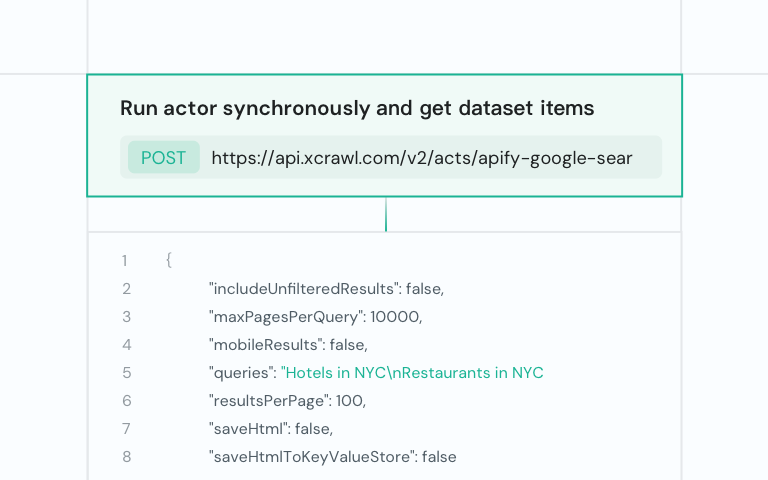
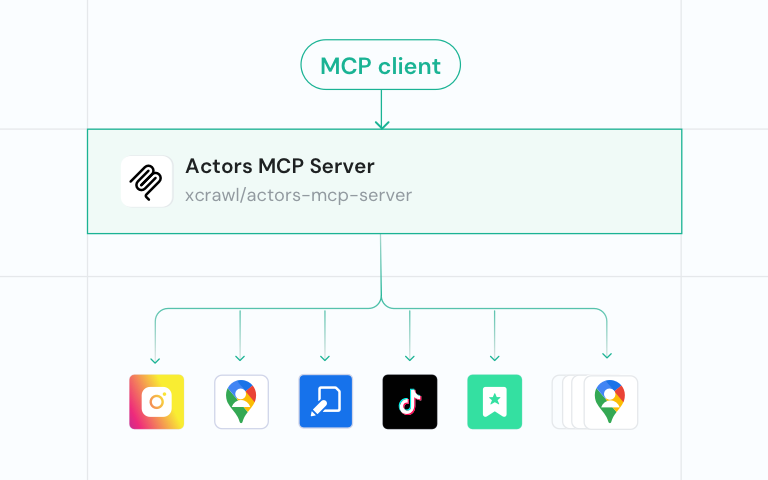
一体化抓取 API,支持超 100 个域名,交付结构化数据,全托管且轻松扩展
真实用户行为模拟,完美绕过反爬
即时抓取实时搜索结果,无需任何配置
一键高清视频捕获,速度提升 10 倍
为大语言模型持续提供最新数据
为您的网站提供即开即用的 AI 聊天
联系方式自动化抓取
快速追踪品牌情感
实时获取竞争对手洞察
用真实网络数据驱动 AI
让市场数据真正可行动
100+ 域名专用端点
查找常见问题解答
快速上手 Xcrawl
探索产品资讯与动态
利用数千个预制与可定制 Actor 构建大规模网页抓取与浏览器自动化工作流,将实时网页内容转为可靠、可直接用于 API 的数据,用于模型训练、CRM 赋能、竞争监测、聊天机器人与自动化任务。
support@xcrawl.com