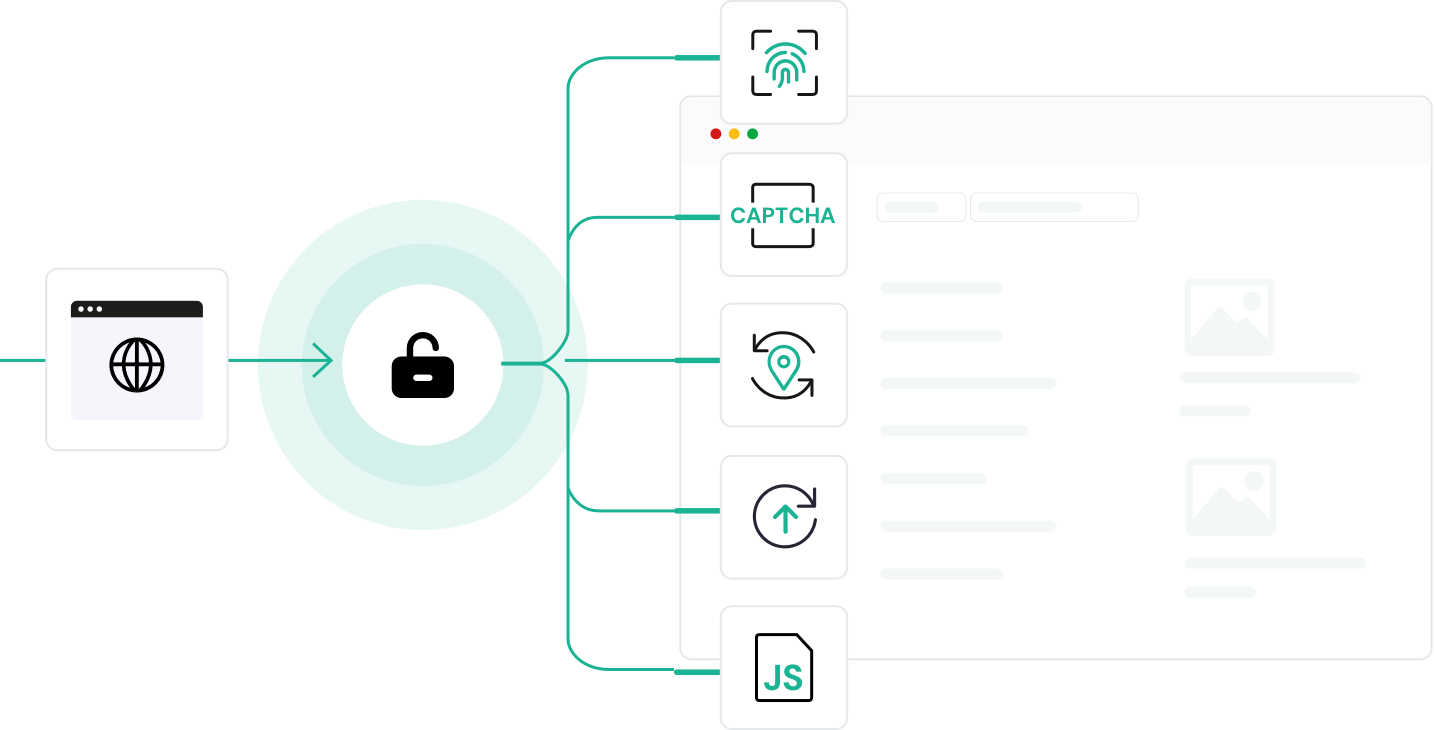
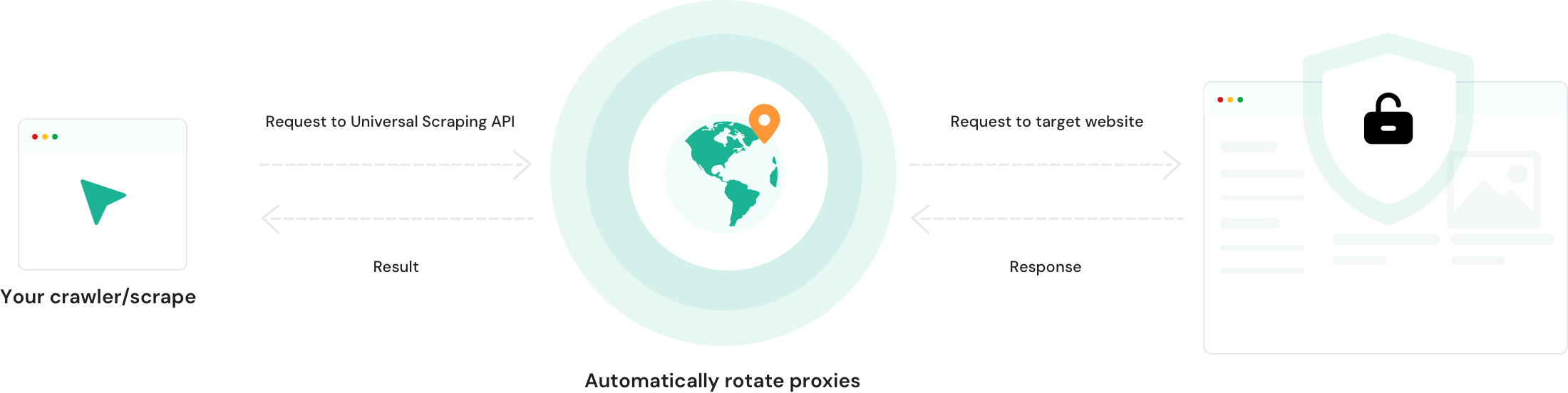
Xcrawl 的网页抓取 API 比我们之前用过的所有工具表现都更好。实时数据和反爬保护都非常出色。
我们的 AI Agent 全靠 Xcrawl 提供 SERP API 和大规模爬取能力,集成过程非常轻松。
反爬规避能力是我们测试过最强的。那些难搞的网站已经不再是问题。
非常适合需要实时网页数据的 AI 工作流。返回的 JSON 始终干净整齐。
社交媒体抓取表现很强。我们能大规模稳定地提取帖子和互动数据。
在价格监控和竞品分析上非常可靠。Web Scraper API 稳如磐石。
以前卡在大量 CAPTCHA 的站点,现在 Xcrawl 都能自动处理了。
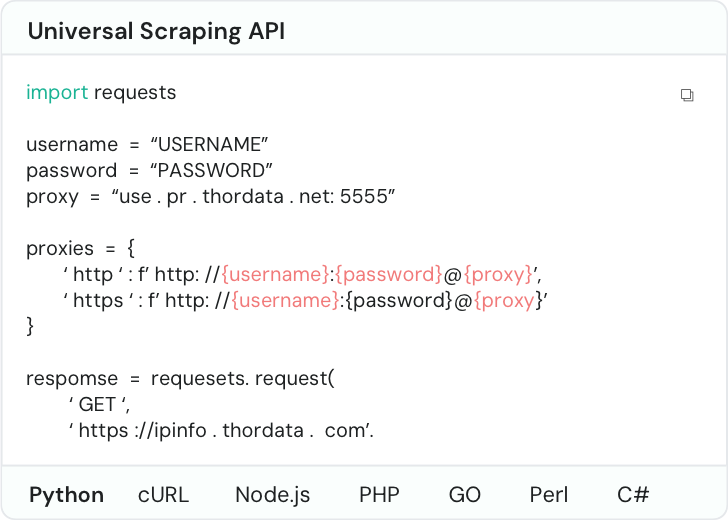
通用抓取端点帮我们节省了大量开发时间。一个 API 解决全部问题。
我们把实时网页数据输送给 AI Agent,模型的判断准确率提升明显。
SERP API 快速且准确,非常适合关键词监控与 SEO 分析。
JS 重站点加载完美,比我们旧的 puppeteer 方案强太多。
内置的数据管道特别好用,推送到 S3 或 GCS 都非常顺畅。
我们的自动化机器人依赖 Xcrawl 获取跨平台的社交数据,非常稳定。
我们把多个自研爬虫全部替换为 Xcrawl,维护成本几乎降为零。
从第一天开始团队就能高效使用,多亏了清晰的 API 和文档。
即使在高负载下,API 依旧稳定快速,令人印象深刻。
Xcrawl 的网页抓取 API 比我们之前用过的所有工具表现都更好。实时数据和反爬保护都非常出色。
我们的 AI Agent 全靠 Xcrawl 提供 SERP API 和大规模爬取能力,集成过程非常轻松。
反爬规避能力是我们测试过最强的。那些难搞的网站已经不再是问题。
非常适合需要实时网页数据的 AI 工作流。返回的 JSON 始终干净整齐。
社交媒体抓取表现很强。我们能大规模稳定地提取帖子和互动数据。
在价格监控和竞品分析上非常可靠。Web Scraper API 稳如磐石。
以前卡在大量 CAPTCHA 的站点,现在 Xcrawl 都能自动处理了。
通用抓取端点帮我们节省了大量开发时间。一个 API 解决全部问题。
我们把实时网页数据输送给 AI Agent,模型的判断准确率提升明显。
SERP API 快速且准确,非常适合关键词监控与 SEO 分析。
JS 重站点加载完美,比我们旧的 puppeteer 方案强太多。
内置的数据管道特别好用,推送到 S3 或 GCS 都非常顺畅。
我们的自动化机器人依赖 Xcrawl 获取跨平台的社交数据,非常稳定。
我们把多个自研爬虫全部替换为 Xcrawl,维护成本几乎降为零。
从第一天开始团队就能高效使用,多亏了清晰的 API 和文档。
即使在高负载下,API 依旧稳定快速,令人印象深刻。