获得免维护的采集基础设施
受益于我们基于 AI 驱动的网页数据采集基础设施,可立即使用。
无需开发或维护采集器与浏览器
自动绕过反爬系统
把资源专注用于数据分析

受益于我们基于 AI 驱动的网页数据采集基础设施,可立即使用。
使用 Xcrawl Web Scraper API,您可以从最复杂的网站提取大规模结构化数据。准确无缺失,是我们对数据质量的保证。
无需再自建或维护采集基础设施。直接提取海量网页数据,确保扩展性与可靠性。
API for finding YouTube videos by searching with specific keywords or phrases.
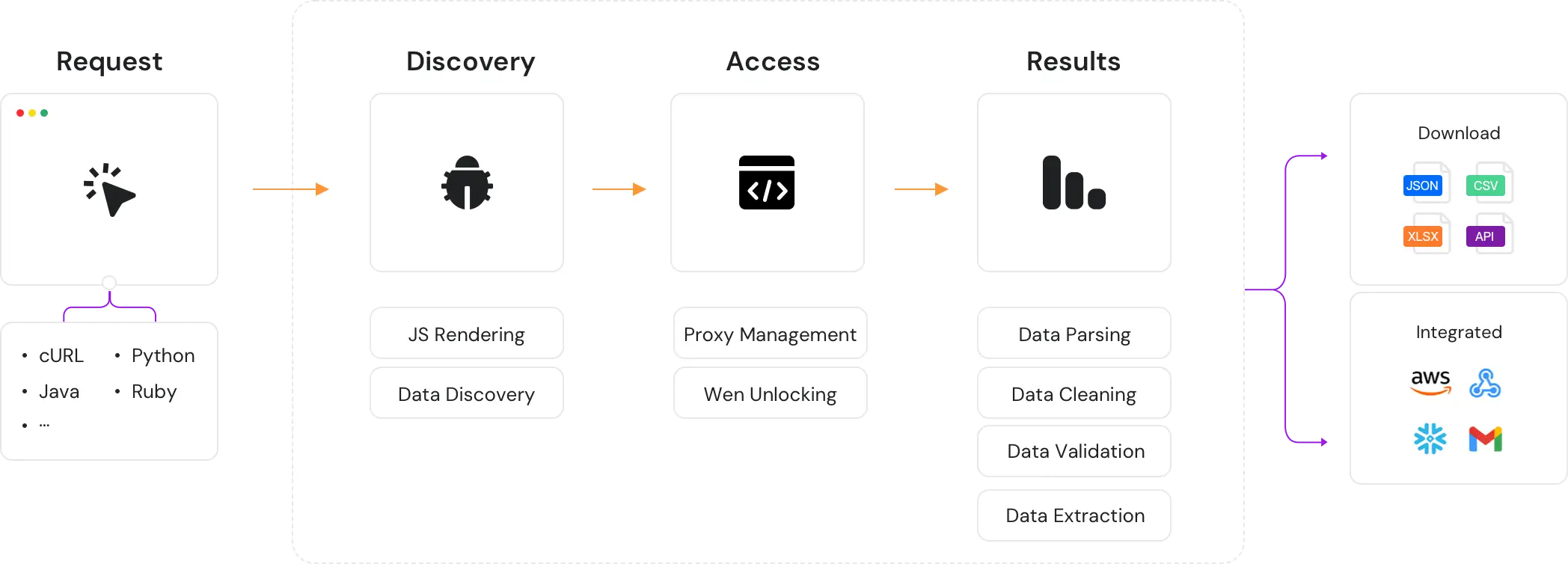
从复杂网站获取数据从未如此简单。通过示例了解 Web Scraper API 的强大能力。
curl -X POST https://xcrawl.com -H "Authorization: YOU_TOKEN" -H "Content-Type: application/json" -d "{\"source\":\"amazon_product_detail\",\"geo\":\"US\",\"context\":{\"product_url_list\":[{\"product_url\":\"https://www.amazon.com/-/zh/dp/B0CRJJBBPY/ref=sr_1_1?__mk_zh_CN=%E4%BA%9A%E9%A9%AC%E9%80%8A%E7%BD%91%E7%AB%99&crid=3GT62OEZ1P8UY&dib=eyJ2IjoiMSJ9.1xI_eGcwVfHyp42_ohr319CE_BqdP9iZwzJtC6yFSyQ0G_tjyzg4rJ26GSTHz44QoDmmQu3QQZT3Hm2XEsp7vc9wEdRTCZ6ZNwfpPM334J0kRdDhcQMXCmoZiiGF4gQb-LMQ1nJecrasxT1jB75moxnqMPXWOjVkKvRejjISu4Z-5XNLRRhL6XH1yQWAfGGRbe5PKrmAvh2--XWShlbHUYuX5K_Fts08p1qUDYfbYgE.F8jz9PUZ8OXvrGl_3STCKqGApD4gYPB7WDw_N6iif2A&dib_tag=se&keywords=iPhone%2B15%2BPro%2BMax&qid=1762833248&sprefix=iphone%2B15%2Bpro%2Bmax%2Caps%2C674&sr=8-1&th=1\"}]}}"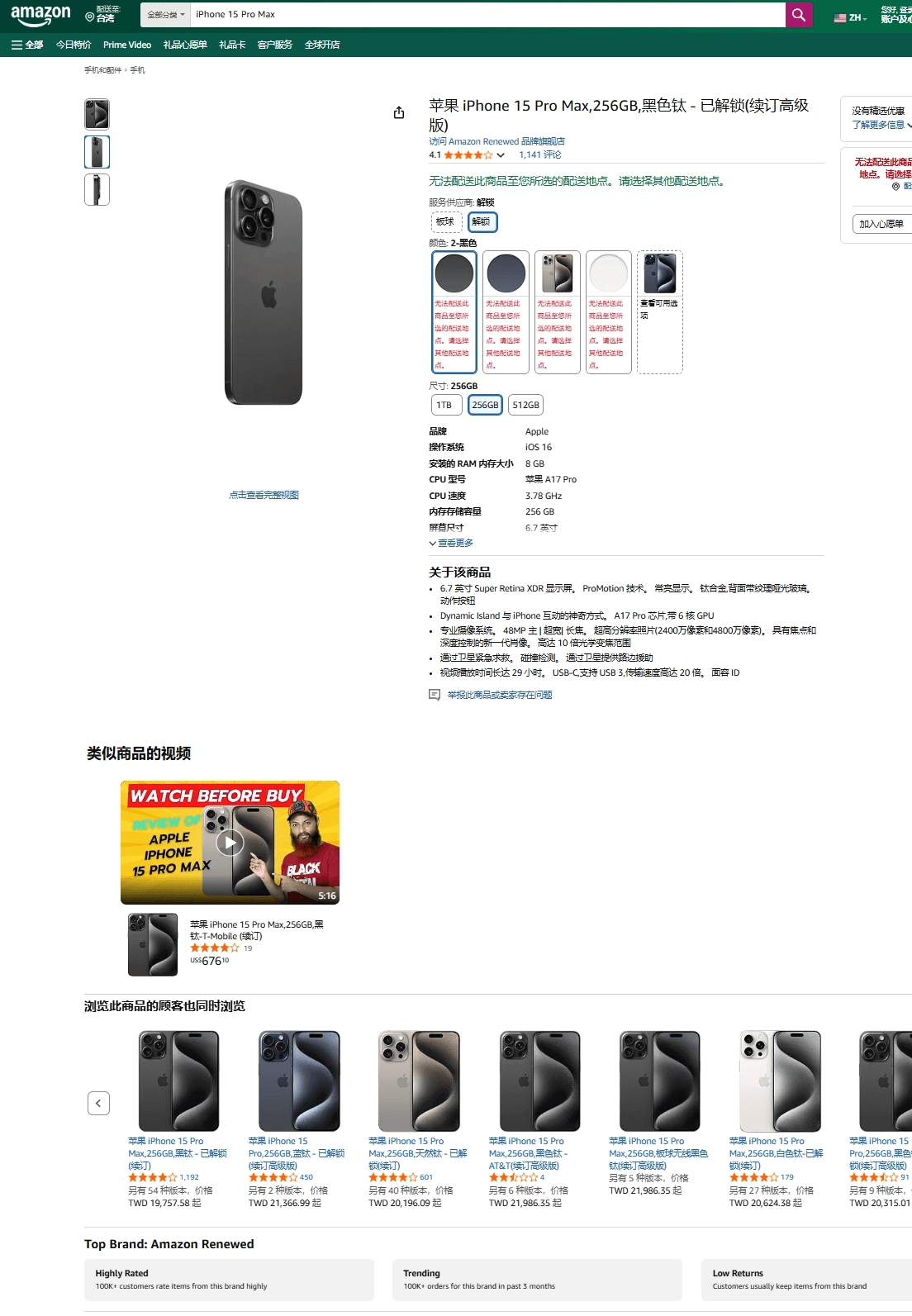
从复杂网站获取数据从未如此简单。通过示例了解 Web Scraper API 的强大能力。
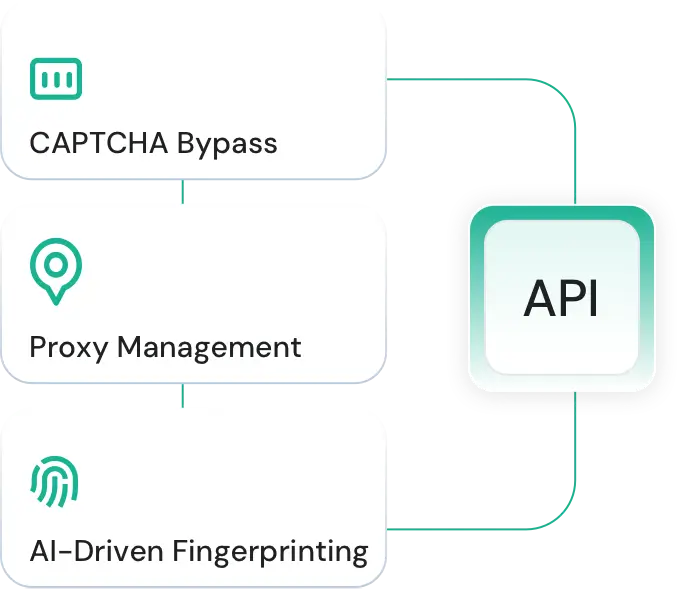
基于机器学习的代理选择与轮换,使用覆盖 190 个国家的高级代理池。
独特的 HTTP Header、JavaScript 与浏览器指纹,使系统更能适应动态内容。
自动重试与验证码绕过,保证数据持续获取。
一次从多个页面提取数据,每批可处理最多 1 万个 URL。
可通过 SFTP、AWS S3 等云存储接收数据,或通过 API 获取结果。
设置自动化采集频率,数据可直接交付至您的云存储。
无需维护代理或构建采集系统,减少工程负担。
易于集成并支持定制化。
如有任何问题,可随时获得专业支持。
适用于任何规模的安全且可靠的网页数据提取服务。99.95% 在线率,符合 SOC2、GDPR 与 CCPA 要求。






关于 Xcrawl 的所有核心信息。



